Vad är spds?
En enkel programmerbar logikenhet (SPLD) är en kompakt elektronisk komponent som används för att utföra logikfunktioner i elektroniska system.Det är känt för sin enkla struktur och förmåga att behålla konfigurationer även utan ström.I den här artikeln lär du dig om SPLD, dess jämförelser med andra enheter, dess funktioner och hur dess modeller fungerar.Katalog

Introduktion till SPLD
En enkel programmerbar logikenhet (SPLD) är en typ av integrerad krets utformad för att utföra en mängd logikoperationer.Även om det liknar en komplex PLD (CPLD), kommer en SPLD vanligtvis med färre ingångs-/utgångsstift och programmerbara element.Detta gör det mer krafteffektivt och enklare i strukturen.
För att konfigurera en SPLD behöver du ofta en specifik programmeringsenhet.Tillverkare kan ha sina unika metoder för att programmera dessa enheter, så att processen kan variera.Trots detta är ett vanligt inslag i SPLD: er att de är icke-flyktiga.Detta innebär att de kan hålla sin konfiguration intakt även när strömmen är avstängd.
Inuti en SPLD hittar du en samling programmerbara logikgrindar och punkter, som gör att den kan utföra olika uppgifter.Många SPLD: er inkluderar också minneselement och flip-flops, vilket lägger till deras mångsidighet när det gäller att skapa både logik- och minnesbaserade mönster.
Jämförelse av SPLD med andra plds
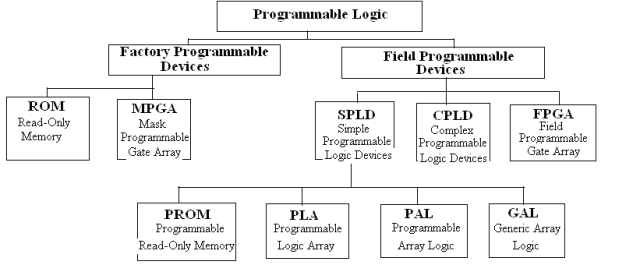
Programmerbara logikenheter (PLD) är en bred kategori som innehåller flera typer av enheter såsom programmerbart skrivskyddsminne (PROM), Erasable Programmerable Reit-Only Memory (EPROM), Programmerbar Logic Array (PLA), Programmerable Array Logic (PAL) (PAL)och generisk matrislogik (GAL).Varje typ är utformad med unika strukturella funktioner och funktioner, som sammanfattas i tabellen nedan.
Strukturen för en PLA delar likheter med en prom.Båda har ett arrangemang av och grindar eller grindar och utgångsbuffertar.Emellertid är och grinduppsättningen i en PLA programmerbar och erbjuder mer flexibilitet.När du bygger samma logikfunktioner använder PLAS vanligtvis färre celler i AND- och GATE -matriserna jämfört med PROM, vilket gör dem mer effektiva för vissa applikationer.
PAL -enheter inkluderar å andra sidan ibland en registrerad utgångsstruktur.Detta gör att de kan hantera både kombinerande och sekventiella logikuppgifter, vilket gör dem lämpliga för ett bredare utbud av mönster.GAL-enheter tar mångsidighet ett steg längre med sina programmerbara makro-logiska enheter, som erbjuder olika operativa lägen.Dessa lägen kan replikera de olika utgångsstrukturerna som finns i PAL -enheter.
Medan programmeringspal och GAL-enheter kan vara komplexa på grund av behovet av dedikerade verktyg och programmeringsspråk, är dessa verktyg utformade för att vara användarvänliga.Detta gör att arbeta med PAL och GAL -enheter tillgängliga, även med deras avancerade kapacitet.
Översikt över Atmel SPLD
ATMEL SPLD -produkter, såsom 16V8 och 22V10, är utformade för att uppfylla industristandarder och erbjuda en rad alternativ för olika kraft- och spänningskrav.Dessa inkluderar lågspännings-, nollkrafts- och kvartkraftsversioner, som tillgodoser olika behov.ATMEL tillhandahåller också "L" -seriesenheterna, som har automatisk uppstoppningsfunktion, vilket gör dem mycket energieffektiva.Ett populärt exempel är ATF22LV10CQZ, ett batterivänligt alternativ.
ATMEL SPLDS finns i ett proprietärt TSSOP -paket, som är en av de minsta designen för SPLD -enheter.De stöder också andra vanligt använda förpackningsformat, vilket säkerställer kompatibilitet med olika system.Alla ATMEL SPLD -produkter är byggda med EE -teknik, vilket säkerställer tillförlitlig prestanda och repeterbar programmering.Dessutom stöds de av allmänt tillgängliga programmeringsverktyg från tredje part, vilket gör dem enkla att arbeta med.
Förstå SPLD -modeller
SPLD -modeller är utformade för att fokusera på mångfald inom prover genom att säkerställa att utvalda prover är så varierande som möjligt.Denna mångfald är baserad på idén att prover inom samma grupp eller kluster tenderar att vara mer lik varandra jämfört med de från olika grupper.Denna klustermetod hjälper till att fånga ett brett utbud av beteenden och mönster i data.
Till exempel, i en videonigenkänningsuppgift, betraktas ramar från samma video som en del av samma kluster på grund av deras likheter.Å andra sidan uppvisar ramar från olika videor mångfald eftersom de tillhör olika kluster.Detta koncept gäller SPLD, där datauppsättningen är uppdelad i kluster, och systemet tilldelar värden till prover baserat på deras mångfald inom dessa grupper.
Modellen introducerar en parametermatris som distribuerar inlärningsvikterna över flera kluster.Detta säkerställer att utvalda prover täcker ett brett spektrum av data snarare än att koncentreras i ett kluster.Det gör det möjligt för SPLD: er att balansera mellan enkelhet (tilldela vikter till enkla prover) och variation (välja från flera grupper).
Ett unikt drag i SPLD är dess användning av en objektiv funktion som främjar mångfald genom en metod som kallas negativ L2,1 -norm.Till skillnad från traditionella SPL: er som kan fokusera på några kluster, uppmuntrar SPLD att sprida provval över så många kluster som möjligt.Detta skapar en rikare inlärningsupplevelse genom att undvika redundans.
SPLD-optimering följer en steg-för-steg-strategi och växlar mellan uppdatering av två uppsättningar parametrar.Genom att rangordna prover baserat på deras förlustvärden och tillämpa en gradvis minskande tröskel, säkerställer SPLD att den inkluderar en blandning av prover, allt från enklare till mer komplex.Denna process säkerställer ett mångsidigt och balanserat urval, som skiljer SPLD från traditionella SPL -metoder.
Optimeringsprocess i SPLD
Optimeringsprocessen i SPLD fokuserar på att förfina hur prover väljs och distribueras över kluster.Det syftar till att balansera mångfald och inlärningseffektivitet genom att lösa ett icke-konvex optimeringsproblem.Detta uppnås genom en objektiv funktion:
Här:
Funktionen är utformad för att minimera förlusten samtidigt som man uppmuntrar ett mångfaldigt provval med två parametrar, och .Dessa kontrollerar balansen mellan att fokusera på enklare prover och säkerställa mångfald.
Eftersom data ofta grupperas i kluster, bryts optimeringsproblemet i mindre underproblem.Varje kluster har sin egen optimeringsuppgift:
Här, representerar förlusten för -Th -provet i kluster .Lösningen säkerställer att varje kluster bidrar med en mångfaldig uppsättning prover till den totala inlärningsprocessen.
För att ytterligare förfina urvalsprocessen rankas prover baserat på deras förlust.En tröskel, bestämd av parametrarna och , justeras dynamiskt när fler prover väljs:
Om ett provförlust uppfyller , det väljs ();Annars är det inte ().
Optimeringen växlar mellan uppdatering och , säkerställa att varje steg förfinar parametrarna för att uppnå bättre resultat.Genom att integrera en minskande tröskel innehåller SPLD prover med högre förlust över tid, vilket säkerställer en blandning av enklare och mer utmanande exempel.Denna metod förbättrar inlärningseffektiviteten samtidigt som man bibehåller provdiversiteten.
Detta strukturerade tillvägagångssätt, i kombination med exakta matematiska definitioner, gör SPLD effektiv för komplexa, heterogena datascenarier.
Om oss
ALLELCO LIMITED
Läs mer
Snabb förfrågan
Skicka en förfrågan, vi svarar omedelbart.

Vad är SRAM?
på 2025/01/14

Adm699Ar Analoga enheter Alternativ, funktioner, applikationer
på 2025/01/14
Populära inlägg
-

Komplexa instruktionsuppsättningsdatorer: Hur de ändrade datoranvändning?
på 8000/04/18 147757
-

USB-C-pinout och funktioner
på 2000/04/18 111936
-

Använda Xilinx Unified Simulation Primitives: En omfattande guide till FPGA -design och simulering
på 1600/04/18 111349
-

Strömförsörjningsspänningar i elektronik: Betydelsen av VCC, VDD, VEE, VSS och GND
på 0400/04/18 83721
-

RJ45 -anslutningsguide: Pinout, ledningar, kabeltyper och användningar
på 1970/01/1 79508
-

Den ultimata guiden för trådfärgkoder i moderna elektriska system
Hur våra elektriska system använder färger är inte bara för utseende.Varje trådfärg indikerar nu en specifik funktion, vilket gör det lättare att identifiera och hantera elektriska komponenter korr...på 1970/01/1 66911
-

Purge Valve Guide: Funktion, symtom, testning och ersättning för optimal motorprestanda
Purge -ventilen är en viktig del av bilens system som hjälper till att hålla luften ren genom att hantera bränsleångor innan de kan fly in i atmosfären.Detta hjälper inte bara miljön genom att mins...på 1970/01/1 63048
-

Kvalitet (Q) Faktor: Ekvationer och applikationer
Kvalitetsfaktorn, eller 'Q', är viktig när man kontrollerar hur väl induktorer och resonatorer arbetar i elektroniska system som använder radiofrekvenser (RF).'Q' mäter hur väl en krets minimerar e...på 1970/01/1 63012
-

Uppnå toppprestanda med den maximala kraftöverföringssatsen
Den maximala kraftöverföringssatsen förklarar hur energi från en källa, till exempel ett batteri eller generator, flyter till en ansluten belastning.Det visar det exakta tillståndet där lasten får ...på 1970/01/1 54081
-

A23 -batterispecifikationer och kompatibilitet
A23-batteriet är ett litet, cylinderformat batteri med högspänning.Även kallad 23A, 23AE eller MN21, den körs vid 12 volt och mycket högre än AA- eller AAA -batterier.Dess speciella design...på 1970/01/1 52127
Hett artikelnummer
-

LT8619IMSE#PBF
Analog Devices Inc.
IC REG BUCK 0.8V 1.2A 16MSOP
SN54LS173AJ
Texas Instruments
54LS173A 4-BIT D-TYPE REGISTERS
74AC109SC
Fairchild Semiconductor
IC FF JK TYPE DUAL 1BIT 16SOIC
V375C12E150BG
Vicor Corporation
DC DC CONVERTER 12V 150W
ADM8830ACP
Analog Devices Inc.
IC CHARGE PUMP REG TFT 20LFCSP
Z8F021APJ020SG
Zilog
IC MCU 8BIT 2KB FLASH 28DIP
SPC58EC80E1Q0C0X
STMicroelectronics
IC MCU 32BIT 4MB FLASH 64ETQFP
VE-2N2-CW
Vicor Corporation
DC DC CONVERTER 15V 100W
NZT902
onsemi
TRANS NPN 90V 3A SOT223-4
EDZVFHT2R16B
Rohm Semiconductor
DIODE ZENER 16V 150MW EMD2
ATMEGA329PV-10ANR
Atmel
IC MCU 8BIT 32KB FLASH 64TQFP
MM74HCT08MTCX
Fairchild Semiconductor
AND GATE, HCT SERIES, 4-FUNC, 2-
UC3853D
Texas Instruments
IC PFC CTR AVER CURR 94KHZ 8SOIC
MT46V8M16TG-75:D
Micron Technology Inc.
IC DRAM 128MBIT PARALLEL 66TSOP
DRV5015A1QDBZT
Texas Instruments
MAGNETIC SWITCH LATCH SOT23-3
TPS7A2430DBVR
Texas Instruments
IC REG LINEAR 3V 200MA SOT23-5
10118242-001RLF
Amphenol ICC (FCI)
CONN RCP MICRO HDMI 19POS SMD RA
NUF6402MNT1G
onsemi
FILTER RC(PI) 100 OHM/17PF SMD -

MAX923CPA+
Analog Devices Inc./Maxim Integrated
IC COMPARATOR 2 W/VOLT REF 8DIP
SL28506BZC-2
Skyworks Solutions Inc.
IC CLOCK CK505 PCIE GEN2 56TSSOP
LT1678CS8#TRPBF
Analog Devices Inc.
IC OPAMP GP 2 CIRCUIT 8SO
RHRG5060
NXP USA Inc.
RECTIFIER DIODE, AVALANCHE, 1 PH
TLC3704CN
Texas Instruments
IC COMPARATOR 4 GEN PUR 14DIP
W1524LC300
IXYS
DIODE GEN PURP 3KV 1524A W4
TPS2041BDBVR
Texas Instruments
IC PWR SWITCH N-CHAN 1:1 SOT23-5
VI-250-EY
Vicor Corporation
DC DC CONVERTER 5V 50W
RMPA0959
Fairchild Semiconductor
IC RF AMP CELL 824-849MHZ 11LCC
SMCJ16CA-E3/57T
Vishay General Semiconductor - Diodes Division
TVS DIODE 16VWM 26VC DO214AB
SN74CBT3125PWR
Texas Instruments
IC BUS SWITCH 1 X 1:1 14TSSOP
ACT412US-T
Active-Semi
IC OFF-LINE SWITCH PWM 6SOT-23
VNB14NV0413TR
STMicroelectronics
IC PWR DRIVER N-CHAN 1:1 D2PAK
C1608X7R2A102M/10
TDK Corporation
CAP CER 1000PF 100V X7R 0603
C2012JB1A685K085AC
TDK Corporation
CAP CER 6.8UF 10V JB 0805
EPM3128ATC100-5
Intel
IC CPLD 128MC 5NS 100TQFP
LTC2950ITS8-2#TRMPBF
Analog Devices Inc.
IC PB ON/OFF CONTROLLER TSOT23-8
BLM21BB221SN1D
Murata Electronics
FERRITE BEAD 220 OHM 0805 1LN -

THS6226AIRHBT
Texas Instruments
IC TELECOM INTERFACE 32VQFN
LV8481CS-TE-L-H
onsemi
IC MTR DRVR BIPLR 2.4-4.5V 10WLP
SSF2300
Good-Ark Semiconductor
MOSFET, N-CH, SINGLE, 4.5A, 20V,
CYPD2134-24LQXI
Infineon Technologies
IC MCU 32BIT 32KB FLASH 24QFN
SBR20A100CT
Diodes Incorporated
DIODE ARRAY SBR 100V 10A TO220AB
93LC46B-I/MS
Microchip Technology
IC EEPROM 1KBIT MICROWIRE 8MSOP
74HCT1G14GV,125
Nexperia USA Inc.
IC INVERT SCHMITT 1CH 1-IN SC74A
L78M09CDT-TR
STMicroelectronics
IC REG LINEAR 9V 500MA DPAK
HRPG-ASCA#13R
Broadcom Limited
ROTARY ENCODER OPTICAL 120PPR
IRFR9220TRPBF
Vishay Siliconix
MOSFET P-CH 200V 3.6A DPAK
ISL81487LIB
Intersil
IC TRANSCEIVER HALF 1/1 8SOIC
UPD78F0511AGB-GAF-AX
Renesas Electronics America Inc
IC MCU 8BIT 16KB FLASH 44LQFP
PCM1737E/2K
Texas Instruments
IC DAC/AUDIO 24BIT 200K 28SSOP
V24B15H200BG3
Vicor Corporation
DC DC CONVERTER 15V 200W
AB-13.560MANH-T
TXC CORPORATION
CRYSTAL 13.5600MHZ 15PF SMD
XC6220B281PR-G
Torex Semiconductor Ltd
IC REG LINEAR 2.8V 1A SOT89-5
KSZ9131RNXC
Microchip Technology
IC TXRX FULL/HALF 4/4 48QFN
12062C223MAT2A
KYOCERA AVX
CAP CER 0.022UF 200V X7R 1206